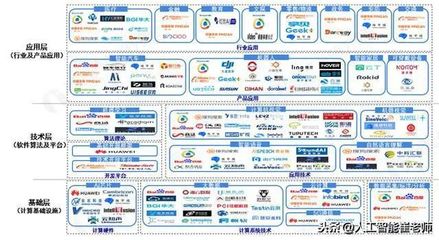
人工智能技術開發人員應遵循的7條道德準則
隨著人工智能技術的飛速發展,其對社會、經濟乃至人類生活的深刻影響日益凸顯。作為推動這一變革的核心力量,人工智能技術開發人員,尤其是從事基礎軟件開發的工程師與研究者,肩負著確保技術向善、造福人類的重要責任。因此,在構建智能未來的基石時,遵循明確的道德準則不僅是職業要求,更是時代賦予的使命。以下是在人工智能基礎軟件開發過程中,開發人員應恪守的七條核心道德準則。
1. 透明性與可解釋性原則
人工智能系統,尤其是底層算法和模型,應盡可能具備透明性和可解釋性。開發人員有責任使系統的決策邏輯能夠被人類理解、審查和質疑。這意味著在設計和實現過程中,應記錄數據來源、算法選擇、模型訓練過程以及關鍵參數,并努力開發使黑箱決策過程“白盒化”的工具和方法。透明是建立信任的基石,也是進行有效監管和問責的前提。
2. 公平性與無偏見準則
開發人員必須致力于識別和消除人工智能系統中的偏見,確保其決策對所有用戶群體公平。這要求從數據采集的源頭開始審視,警惕數據集中可能存在的歷史性、社會性偏見。在算法設計階段,應主動納入公平性評估指標,并進行針對性的測試與校正,防止系統因種族、性別、年齡、地域等因素對個體產生不公正的待遇或歧視性結果。
3. 安全與可靠性準則
人工智能基礎軟件是上層應用的支柱,其安全與可靠性至關重要。開發人員必須將安全性融入開發全生命周期,確保系統能夠抵御惡意攻擊、對抗性樣本的干擾,并在預期及非預期場景下保持魯棒性和穩定性。系統應具備失效保護機制,在出現錯誤或失控時,能夠安全降級或停止,避免造成不可控的物理傷害或社會危害。
4. 隱私保護與數據治理準則
人工智能的開發高度依賴數據。開發人員必須嚴格遵守數據隱私保護法律法規(如GDPR等),貫徹“隱私設計”理念。這意味著在系統架構之初,就應將數據最小化、匿名化、加密存儲和訪問控制等原則作為核心設計要素。開發者不僅是代碼的編寫者,更是用戶數據的受托人,有責任建立清晰的數據使用協議,并確保數據在其整個生命周期內得到妥善治理。
5. 責任與問責準則
明確的責任鏈條是人工智能倫理的關鍵。開發人員應清晰地界定自身在開發環節的責任,并與產品經理、測試人員、法務及最終部署方共同構建完整的問責體系。當人工智能系統產生不良后果時,應有機制追溯問題根源,無論是數據、算法、模型還是部署環境的問題,相關責任方都應能承擔相應的技術、法律和道德責任。
6. 人類福祉與可控性準則
人工智能的發展終極目標應是增進人類福祉。開發人員應始終將“人類在環路中”作為重要設計原則,確保人類對關鍵決策保有最終的控制權和否決權。特別是在高風險領域(如醫療、交通、司法),系統應作為人類的輔助工具而非完全自主的決策者。開發過程應持續評估技術的社會影響,防止其被用于侵犯人權、加劇社會不平等或從事其他有悖于人類整體利益的活動。
7. 可持續發展與社會公益準則
人工智能的開發應考慮環境成本與社會效益。在基礎軟件層面,應致力于開發能效更高、計算資源需求更優的算法與框架,減少碳足跡。開發人員應積極思考如何利用自身技能解決社會面臨的重大挑戰,如氣候變化、疾病防控、教育普惠等,并考慮將部分技術成果以開源、公益的形式共享,促進知識傳播和技術普惠,避免技術鴻溝的進一步擴大。
****
上述七條準則并非孤立存在,而是相互關聯、相輔相成的整體。在人工智能基礎軟件開發的復雜工程實踐中,道德考量應與技術實現深度融合。它要求開發人員不僅具備卓越的技術能力,更需擁有深刻的人文關懷、社會洞察力和倫理反思習慣。通過構建在堅實倫理基礎上的技術,我們才能引導人工智能走向一個真正安全、可信、公平且造福全人類的未來。這不僅是開發者的職業守則,更是我們對這個時代的一份莊嚴承諾。