2017年人工智能基礎軟件開發行業研究報告
2017年是人工智能技術從概念走向大規模應用的關鍵一年,其中,基礎軟件開發作為整個AI產業鏈的核心支撐,迎來了前所未有的發展機遇與深刻變革。本報告旨在系統梳理2017年人工智能基礎軟件開發生態、關鍵技術進展、市場格局及未來趨勢。
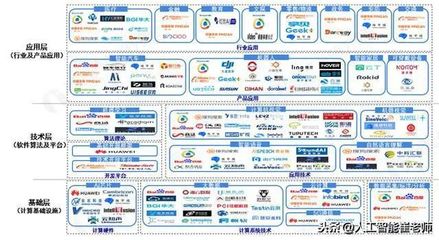
一、 行業生態概覽:開源主導與商業閉環并行
2017年,人工智能基礎軟件的開源生態持續繁榮,并深刻塑造了行業發展路徑。以Google的TensorFlow、Facebook的PyTorch以及伯克利大學的Caffe等為代表的開源框架,憑借其強大的社區支持、靈活的架構和持續的迭代更新,成為了大多數研究機構與企業進行AI研發的首選平臺。這些框架降低了深度學習模型開發、訓練與部署的門檻,極大地加速了AI技術的普及和創新。與此以亞馬遜AWS、微軟Azure、谷歌云為代表的云服務巨頭,以及國內的百度、阿里、騰訊、華為等科技企業,紛紛基于開源核心或自研技術,構建了集成了計算資源、數據服務、開發工具和預訓練模型的一體化AI云平臺(AI-as-a-Service),形成了強大的商業閉環。開源與商業化服務相互促進,共同構成了2017年AI基礎軟件開發的二元驅動生態。
二、 關鍵技術進展:從訓練到部署的全棧優化
在技術層面,2017年的AI基礎軟件開發呈現出明顯的“全棧化”和“工程化”趨勢。
- 模型訓練框架的成熟與分化:TensorFlow和PyTorch成為兩大主流。TensorFlow憑借其強大的生產部署能力、完善的工具鏈(如TensorBoard可視化工具)和跨平臺支持,在工業界占據優勢。而PyTorch則因其動態計算圖帶來的靈活性和直觀的編程接口,在學術界和快速原型開發中備受青睞。這種分化反映了開發者在研究靈活性與工程穩健性之間的不同權衡。
- 推理部署與邊緣計算的興起:隨著AI應用從云端向移動端、物聯網設備等邊緣側延伸,模型的高效部署成為關鍵挑戰。2017年,針對模型壓縮(如剪枝、量化)、加速推理的專用工具和運行時環境(如TensorFlow Lite、Core ML)開始嶄露頭角。芯片廠商(如英偉達的TensorRT)與框架開發者緊密合作,致力于實現從軟件到硬件的協同優化,提升推理效率。
- 自動化機器學習(AutoML)的初步探索:為了進一步降低AI應用開發對專業人才的依賴,自動化機器學習工具開始受到關注。谷歌云AutoML等服務的推出,旨在通過自動化模型架構搜索、超參數調優等復雜過程,讓開發者僅需提供數據即可獲得定制化模型,這代表了基礎軟件向更高層次抽象和易用性邁進的重要一步。
- 數據處理與特征工程工具:圍繞數據這一AI核心燃料,用于大規模數據預處理、清洗、標注和管理的工具鏈(如Apache Spark MLlib的擴展應用)也在不斷完善,與模型開發流程的集成度日益提高。
三、 市場格局與競爭態勢
2017年,全球AI基礎軟件市場呈現“巨頭領跑,多方競逐”的格局。
- 云服務商(CSP):憑借其龐大的云計算基礎設施、海量數據和豐富的企業服務經驗,成為AI基礎軟件服務最主要的提供者和生態構建者。它們通過提供全托管的機器學習服務,將AI能力無縫嵌入到企業現有的IT系統中。
- 傳統軟件與芯片巨頭:如微軟(通過Azure及Cognitive Services)、英特爾(通過收購Nervana等優化其軟件棧)、英偉達(CUDA及GPU加速庫)等,利用其軟硬件優勢,深度整合AI能力。
- 垂直領域與初創企業:在計算機視覺、自然語言處理、機器人等特定領域,也涌現出一批提供專用SDK、API或開發平臺的初創公司,它們憑借對垂直場景的深度理解,在巨頭生態的縫隙中尋找機會。
競爭焦點從單一框架的技術先進性,擴展到開發體驗的流暢性、端到端解決方案的完整性、對異構計算硬件的支持度以及商業模式的創新性。
四、 挑戰與未來展望
盡管發展迅速,2017年的AI基礎軟件開發仍面臨諸多挑戰:人才短缺、模型開發與部署的復雜性、數據隱私與安全、不同框架間的生態壁壘等。
報告預測人工智能基礎軟件開發將呈現以下趨勢:
- 框架的融合與標準化:為解決碎片化問題,跨框架的中間表示(如ONNX)將促進模型在不同生態間的遷移和互操作。
- 低代碼/無代碼開發平臺普及:AutoML和可視化拖拽工具將使AI應用開發更加民主化,吸引更廣泛的開發者群體。
- 軟硬件協同設計深化:針對特定場景(如自動駕駛、安防)的專用AI芯片(ASIC)將催生與之深度綁定的高效軟件棧。
- 安全、可解釋性與倫理工具集成:隨著AI應用深入社會,基礎軟件將逐步內置模型審計、偏見檢測、可解釋性分析等關乎信任與合規的工具。
2017年是人工智能基礎軟件開發從技術驅動走向生態與商業驅動的重要分水嶺,它為后續幾年AI技術在各行各業的深度融合與規模化落地奠定了堅實的軟件基石。